Vyhodnocení výrazu
Stále se rozhlížím po jednoduchém pravidle, vysvětlujícím proces vyhodnocování v Redu. Aktuálně mám dva oblíbené kandidáty. První je přímočarý a snadno použitelný. Druhý není příliš praktický ale dává nahlédnout (domnívám se) na způsob, kterým interpret Redu "myslí".
1. První oblíbenec:
- Všechny operace s infixovými operátory, které mají pouze hodnoty (nikoliv funkce) jako operandy, jsou vyhodnocovány přednostně. Mají-li tyto infixové výrazy více než dva operandy, jsou vyhodnoceny zleva doprava ( → ) bez žádných preferencí .
- Celý výraz je potom vyhodnocen zprava doleva (← ).
>> square-root 2 + 2 + square-root 3 * 3 * square-root 1 + 4 * 5 == 3.272339214155429

2. Druhý oblíbenec se třemi koncepty:
Zdá se, že to chodí ale mám pochybnosti o formální správnosti, neboť si nejsem jist, že každý infixový operátor má přesně korespondující operaci funkce.
První koncept: Vždy zleva doprava →
V Redu se všechno vyhodnocuje zleva do prava. Neexistuje žádný systém preferencí jako u jiných jazyků (např. se násobení neprovádí automaticky přen sčítáním). Přednost v pořadí si ovšem lze vynutit závorkami.
>> 2 + 3 * 5
== 25
>> 2 + (3 * 5)
== 17
Nejenom výrazy ale celý kód programu je vyhodnocován zleva doprava.
Infixové operátory"+", "-", "*", "/" jsou infixové operátory. Korespondují s funkcemi add , multiply, divide a subtract, jež vyžadují dva argumenty: 3 + 2 je totéž ako add 3 2 5 * 8 je totéž jako multiply 5 8 ... ...a tak dále. 2 + 3 * 5 je pouze více čitelná forma výrazu multiply add 2 3 5 . Interpret Redu si potřebnou konverzi provede sám. |
Druhý koncept: Vyhodnotitelné skupiny.
V určité části kódu se vyskytují skupiny slov, které lze dílčí exekucí redukovat na základní datový typ. Například [square-root 16 8 + 2 8 / 2 77] se ve skutečnosti skládá ze čtyř vyhodnotitelných skupin: square-root 16 ; 8 + 2 ; 8 / 2 a 77. Popisovanou redukci lze provést příkazem reduce:
>> a: [ square-root 16 8 + 2 8 / 2 77]
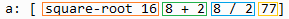
>> reduce a -> [4.0 10 4 77]
Třetí koncept: Funkce si vybírají své argumenty z vyhodnotitelných skupin
Funkce si vybírá své argumenty z následných skupin hodnot či výrazů (počet očekávaných argumentů je potřebné znát) v pořadí zleva doprava. Výrazy jsou před použitím funkcí redukovány na hodnoty.

Důsledkem tohoto přístupu je to, že výsledkem výrazu
square-root 16 + square-root 16
není 8, jak by mnozí očekávali, ale 4.47213595499958, protože Red vidí něco jako toto:

čímž je funkce pro jeden argument, stojící před skupinou s infixovým operátorem (majícím přednost); operandy operátoru (+) jsou číslo a funkce, která se před použitím operátorem vyhodnotí.
Abychom získali oněch intuitivních 8, musíme použít závorky:
>> (square-root 16) + square-root 16
== 8.0
Alternativní sekvenci
>> square-root add 16 square-root 16
== 4.47213595499958
můžeme číst jako
>> square-root (add 16 (square-root 16)) --> 4.47213595499958
Jiný příklad, kombinující infixový operátor a jemu odpovídající funkci:
>> reduce [add 8 + 2 * 3 8 / 2 divide 16 / 2 2 * 2]
== [34 2]

Poněkud zjednodušený pohled na tok výpočtu:
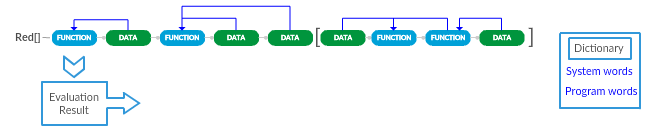
Note: The function that picks data from before it (the third from left to right) refers to infix operators like "+", "-" , "*" , "/" etc.