Uso do parse - Extraindo dados
Contando palavras no texto:
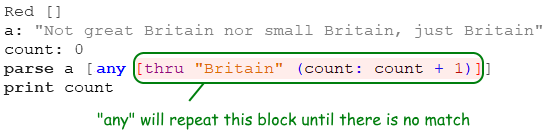
Red []
a: "Not great Britain nor small Britain, just Britain"
count: 0
parse a [any [thru "Britain" (count: count + 1)]]
print count
3
Explicando o programa:
Enquanto thru "Britain" encontrar um "Britain", any vai repetir a regra

Observe que, se você tivesse utilizado to em vez de thru , o input seria movido para ANTES do match, criando um loop infinito , já que o parse ficaria repetindo sempre o match com "Britain".
Extraindo uma parte de um texto:
Para extrair a parte restante de um texto a partir de um determinado ponto, você pode usar word:, como explicado no capítulo Guardando o Input . Para extrair texto entre dois matches do parse, você pode usar copy :
Red []
txt: "They are one person, they are two together"
parse txt [thru "person, " copy b to " two"]
print b
they are
Este é um exemplo muito básico. Eu criei uma página html em helpin.red: http://helpin.red/samples/samplehtml1.html . O html é muito simples e você pode vê-lo digitando print read http://helpin.red/samples/samplehtml1.html no console.
Como conhecemos o html, podemos extrair algumas informações com o código abaixo:
Red []
txt: read http://helpin.red/samples/samplehtml1.html
parse txt [
thru "today"
2 thru ">"
copy weather1 to "<"
thru "tomorrow"
2 thru ">"
copy weather2 to "<"
thru "week"
2 thru ">"
copy weather3 to "<"
]
print {Acording to helpin.red website weather will be: }
print [] ; just adding an empty line
print ["Today: " weather1]
print ["Tomorrow: " weather2]
print ["Next week: " #"^(tab)" weather3] ; just showing the use of tab
Acording to helpin.red website weather will be:
Today: sunny
Tomorrow: horrible
Next week: really really horrible
Mostrarei como o parse funciona para extrair o tempo de "today" para a variável "weather1":
thru "today" ; pula todo o texto até achar o texto "today".
border="1" cellpadding="2" cellspacing="2">
<tbody>
<tr>
<td style="color: black;">weather today:</td>
<td style="color: black;">sunny</td>
</tr>
<tr>
2 thru ">" ; isso faz pular o texto até (depois do) caracter ">". faz isso duas vezes!
border="1" cellpadding="2" cellspacing="2">
<tbody>
<tr>
<td style="color: black;">weather today:</td> ; 1
<td style="color: black;">sunny</td> ; 2
</tr>
<tr>
copy weather1 to "<" ; isso copia para "weather1" tudo que encontra até (antes de) um "<".
border="1" cellpadding="2" cellspacing="2">
<tbody>
<tr>
<td style="color: black;">weather today:</td>
<td style="color: black;">sunny</td> ; ==> weather1
</tr>
<tr>