Avaliação (computação)
Há uma boa descrição da avaliação do Rebol aqui . É praticamente a mesma coisa para o Red. Não vou repetir essa explicação, em vez disso, vou descrever como vejo a avaliação de Red do meu ponto de vista pessoal. Novamente, isso pode ser impreciso, mas até agora explica muito bem o comportamento do Red.
Red, o avaliador furioso!
Uma vez acionado, o Red começará a ler um texto da esquerda para a direita ( → ) executando todas as operações que puder encontrar. Se ele encontrar uma operação que requer argumentos, ele selecionará os argumentos desse texto principal conforme necessário para chegar a um valor final. Dê uma olhada no conceito de grupos avaliáveis e escolha de argumentos . Red considera texto (strings) como um bloco de caracteres, então este texto principal do código é apenas um grande bloco para o Red, mesmo sem colchetes ou aspas.
O que dispara a fúria do Red?
Red é acionado pelo "commando" do. Você nem sempre tem que realmente digitá-lo, quando você executa um script ou pressiona enter no console, o que está acontecendo é que você está aplicando do implícito no texto à frente. No caso de um script, a avaliação só começa depois que o interpretador encontra os caracteres "Red ["
Uma consequência interessante de tudo isso é que, embora geralmente não seja considerada boa prática, você pode realmente executar o texto:
>> do "3 + 5"
== 8
>> 3 + 5 ;same thing. The "do" is implicit and input is text (but not a string! datatype).
== 8
Se é uma computação, qual é o resultado?
O resultado de uma computação em Red é o valor resultante do último grupo avaliável. É claro que você pode fazer todo tipo de coisas interessantes ao longo do caminho, como escrever arquivos, ler páginas da web e criar belos desenhos na tela, mas o valor retornado pelo Red (se houver um) é esse último resultado.
>> do "3 + 5 7 * 8 print 69"
69
O que detém a fúria de Red?
O final do texto (código) e os comentários, é claro.
Mas a avaliação do Red também pula blocos (blocks) dentro do texto principal, deixando-os como estão. Só os avalia se são o argumento de uma operação, observando que esta operação pode ser outro do:
>> do {print "hello" 7 + 9 [8 + 2]} ; the last result is the unevaluated block
hello
== [8 + 2]
>> do {print "hello" 7 + 9 print [8 + 2]}
hello
10
>> do {print "hello" 7 + 9 do[8 + 2]}
hello
== 10
Você descobrirá que, para desenvolver scripts Red, às vezes precisará dos valores resultantes de todos os grupos avaliados em um bloco, não apenas do último. Você pode conseguir isso com reduce. Ele retorna um bloco com todos os resultados. No entanto, não é como se você aplicasse um do para cada grupo avaliável dentro do bloco, como você pode ver aqui:
>> reduce [3 + 5 7 * 8 print 69]
69
== [8 56 unset]
>> reduce [3 + 5 7 * 8 "print 69"] ; do "print 69" should print 69!
== [8 56 "print 69"]
Ordem de avaliação matemática:
Eu ainda estou procurando uma regra simples para explicar o processo de computação do Red. No momento, eu tenho duas candidatas favoritas. A primeira é bem direta e fácil de usar. A segunda não é muito prática, mas dá uma boa visão de como (eu acho) que o interpretador "pensa", e eu acho que é uma boa ideia dar uma olhada nela para captar alguns conceitos que podem ser úteis
1) Minha regra favorita no momento:
1- Todas as operações com operadores infixos que têm apenas valores (não funções) como operandos, são executadas primeiro. Se estes operadores infixos tem mais de dois operandos, eles são avaliados (resolvidos) da esquerda para a direita, sem precedência, ou seja, por exemplo,a multiplicação não é automaticamente feita antes da soma.
2- Então toda a expressão é calculada da direita para a esquerda (← ).
>> square-root 2 + 2 + square-root 3 * 3 * square-root 1 + 4 * 5
== 3.272339214155429

2) Minha segunda favorita, a explicação dos 3 conceitos:
Parece funcionar, e eu acho que, de alguma forma, é parecida com o que o iterpretador realmente faz.
Não é uma simples regra pode não ser formalmente correta, uma vez que não tenho certeza que todo operador infixo tem uma função correspondente.
Conceito 1: Esquerda para a direita sempre →
Em Red, as coisas são avaliadas (resolvidas) da esquerda para a direita. Não existe ordem de precedência, ou seja, por exemplo, a multiplicação não é necessáriamente feita antes da soma. Se você quiser forçar uma precedência, tem que usar parênteses.
>> 2 + 3 * 5
== 25 ; não 17!
Não apenas as expressões, mas todo o código do programa é avaliado da esquerda para a direita.
Operadores infixos
"+", "-", "*", "/" são chamados operadores infixos. Eles correspondem às funções add , multiply, divide e subtract, que precisam de dois argumentos. Então:
3 + 2 é o mesmo que add 3 2
5 * 8 é o mesmo que multiply 5 8 ...
...e assim por diante.
2 + 3 * 5 é só uma forma mais legível de multiply add 2 3 5 . O interpretador Red faz a conversão para você.
Conceito 2: Grupos avaliáveis (computáveis). (N.T. Tradução horrível de "evaluable groups")
Quando você tem um pedaço de código, existem grupos de palavras que são "avaliáveis" (resolvíveis,l computáveis), isto é, podem ser reduzidos a um datatype básico. Por exemplo [square-root 16 8 + 2 8 / 2 77] é, na verdade, composto de 4 grupos avaliáveis: square-root 16 ; 8 + 2 ; 8 / 2 and 77. Você pode user reduce para "ver" os valores dos quatro grupos:
>> a: [ square-root 16 8 + 2 8 / 2 77]
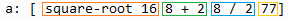
>> reduce a
== [4.0 10 4 77]
Conceito 3: Funções pegam seus argumento dos grupos avaliáveis
Uma função pega seus argumentos dos grupos avaliáveis à sua frente, da esquerda para a direita (pense nos operadores infixos como suas funções correspondentes). Uma função que precisa de 1 argumento, pega o próximo grupo avaliável; uma função que precisa de 2 argumentos, pega os dois próximos grupos avaliáveis, e assim por diante. Note que uma função pode usar um grupo avaliável que tem outra função. Neste caso, a primeira função suspende o seu processamento até que a segunda função seja avaliada, e aí usa o resultado.
Mais uma vez, sem regras de precedência, simplesmente esquerda para direita.

A consequência disso é que uma expressão como...
square-root 16 + square-root 16
... não é 8, como muitos poderiam esperar, mas 4.47213595499958, porque o que o Red vê é:

( ou mesmo: square-root add 16 square-root 16)
Isto é: Uma função que tem um argumento e um grupo avaliável (que por acaso tem uma função dentro).
Para obter aquele 8 intuitivo, é preciso usar parêntesis:
>> (square-root 16) + square-root 16
== 8.0
Outro exemplo, misturando operadores infixos e funções correspondentes:
>> reduce [add 8 + 2 * 3 8 / 2 divide 16 / 2 2 * 2]
== [34 2]

Outras explicações:
Estas são outras regras que eu ví em discussões na internet:
#1
"Esquerda para a direita e operadores tem precedência sobre funções e se um operador infixo vê uma função como seu operando, a resolve primeiro"
#2
"Em geral, as expressões são avaliadas da esquerda para a direita; entretanto, dentro de cada expressão, a computação ocorre da direita para a esquerda"
#3
"Cada expressão pega tantos argumentos quanto precisa. Por sua vez, cada argumento pode ter uma outra expressão e o Red vai fazer o parse da expressão até ter o conjunto completo de argumentos."